
Many of us erroneously believe that launching a website equipped with an XML sitemap will automatically get all its pages crawled and indexed.
In this regard, some myths and misconceptions build up. The most common ones are:
- Google automatically crawls all sites and does it fast.
- When crawling a website, Google follows all links and visits all its pages and includes them all in the Index straight away.
- Adding an XML sitemap is the best way to get all site pages crawled and indexed.
Sadly, getting your website into the Google’s index is a little bit more complicated task. Read on to get a better idea of how the process of crawling and indexation works, and what role an XML sitemap plays in it.
Before we get down to debunking the abovementioned myths, let’s learn some essential SEO notions:
Crawling is an activity implemented by the search engines to track and gather URLs from all over the Web.
Indexation is the process that follows crawling. Basically, it is about parsing and storing Web data that is later used when serving results for search engine queries. The Search Engine Index is the place where all the collected Web data is stored for further usage.
Crawl Rank is the value Google assigns to your site and its pages. It’s still unknown how this metric is calculated by the search engine. Google confirmed multiple times that indexing frequency is not related to ranking, so there is no direct correlation between a websites ranking authority and its crawl rank.
News websites, sites with valuable content, and sites that are updated on a regular basis have higher chances of getting crawled on a regular basis.
Crawl Budget is an amount of crawling resource’s the search engine allocates to a website. Usually, Google calculates this amount based on your site Crawl Rank.
Crawl Depth is an extent to which Google drills down a website level when exploring it.
Crawl Priority is an ordinal number assigned to a site page that signifies its importance in relation to crawling.
Now, knowing all the basics of the process, let’s get those 3 myths behind XML sitemaps, crawling and indexation busted!
Table of Contents
Myth 1. Google automatically crawls all sites and does it fast.
Google claims that when it comes to collecting Web data, it is being agile and flexible.
But truth be told, because at the moment there are trillions of pages on the Web, technically, the search engine can’t quickly crawl them all.
Selecting Websites to Allocate Crawl Budget for
The smart Google algorithm (aka Crawl Budget) distributes the search engine resources and decides which sites are worth crawling and which ones aren’t.
Usually, Google prioritizes trusted websites that correspond to the set requirements and serve as the basis for defining how other sites measure up.
So if you have just-out-of-the-oven website, or a website with scraped, duplicate or thin content, the chances it’s properly crawled are pretty small.
The important factors that may also influence allocating crawling budget are:
- website size,
- its general health (this set of metrics is determined by the number of errors you may have on each page),
- and the number of inbound and internal links.
To increase your chances of getting crawl budget, make sure your site meets all Google requirements mentioned above, as well as optimize its crawl efficiency (see the next section in the article).
Predicting Crawling Schedule
Google doesn’t announce its plans for crawling Web URLs. Also, it’s hard to guess the periodicity with which the search engine visits some sites.
It can be that for one site, it may perform crawls at least once per day, while for some other gets visited once per month or even less frequently.
- The periodicity of crawls depends on:
- the quality of the site content,
- the newness and relevance of information a website delivers,
- and on how important or popular the search engine thinks site URLs are.
Taking these factors into account, you may try to predict how often Google may visit your website.
The role of external/internal links and XML sitemaps
As pathways, Googlebots use links that connect site pages and website with each other. Thus, the search engine reaches trillions of interconnected pages that exist on the Web.
The search engine can start scanning your website from any page, not necessarily from the home one. The selection of the crawl entering point depends on the source of an inbound link. Say, some of your product pages have a lot of links that are coming from various websites. Google connects the dots and visits such popular pages in the first turn.
An XML sitemap is a great tool to build a well-thought site structure. In addition, it can make the process of site crawling more targeted and intelligent.
Basically, the sitemap is a hub with all the site links. Each link included into it can be equipped with some extra info: the last update date, the update frequency, its relation to other URLs on the site, etc.
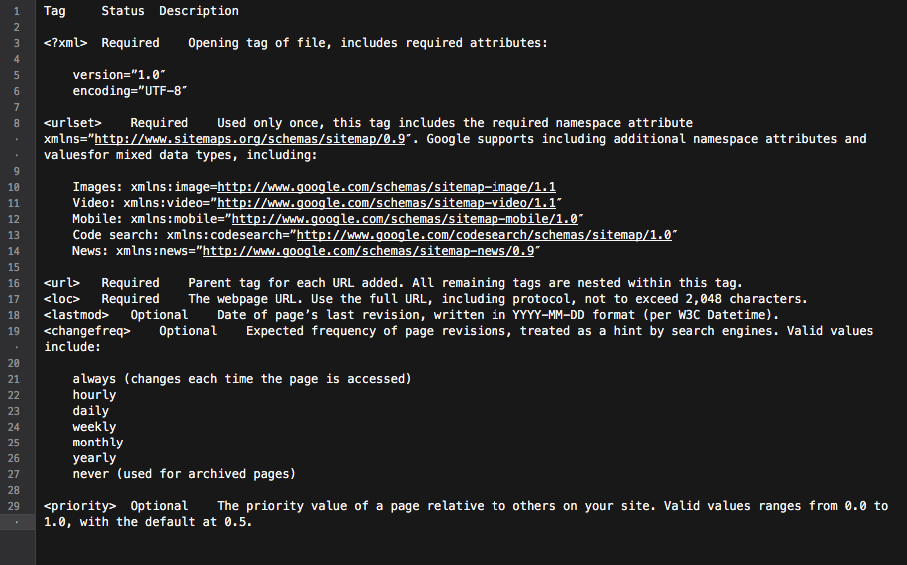 All that provides Googlebots with a detailed website crawling roadmap and makes crawling more informed. Also, all the main search engines give priority to URLs that are listed in a sitemap.
All that provides Googlebots with a detailed website crawling roadmap and makes crawling more informed. Also, all the main search engines give priority to URLs that are listed in a sitemap.
Summing up, to get your site pages on Googlebot’s radar, you need to build a website with great content and optimize its internal linking structure.
Takeaways
• Google doesn’t automatically crawl all your websites.
• The periodicity of site crawling depends on how important or how popular site and its pages are.
• Updating content makes Google visit a website more frequently.
• Websites that don’t correspond to the search engine requirements are unlikely to get crawled properly.
• Websites and site pages that don’t have internal/external links are usually ignored by the search engine bots.
• Adding an XML sitemap can improve the website crawling process and make it more intelligent.
Myth 2. Adding an XML sitemap is the best way to get all the site pages crawled and indexed.
Every website owner wants Googlebot to visit all the important site pages (except for those hidden from indexation), as well as instantly explore new and updated content.
However, the search engine has its own vision of site crawling priorities.
When it comes to checking a website and its content, Google uses a set of algorithms called crawl budget. Basically, it allows the search engine to scan site pages, while savvily using its own resources.
Checking a website crawl budget
It’s quite easy to figure out how your site is being crawled and whether you have any crawl budget issues.
You just need to:
- count the number of pages on your site and in your XML sitemap,
- visit Google Search Console, jump to Crawl -> Crawl Stats section, and check how many pages are crawled on your site daily,
- divide the total number of your site pages by the number of pages that are crawled per day.
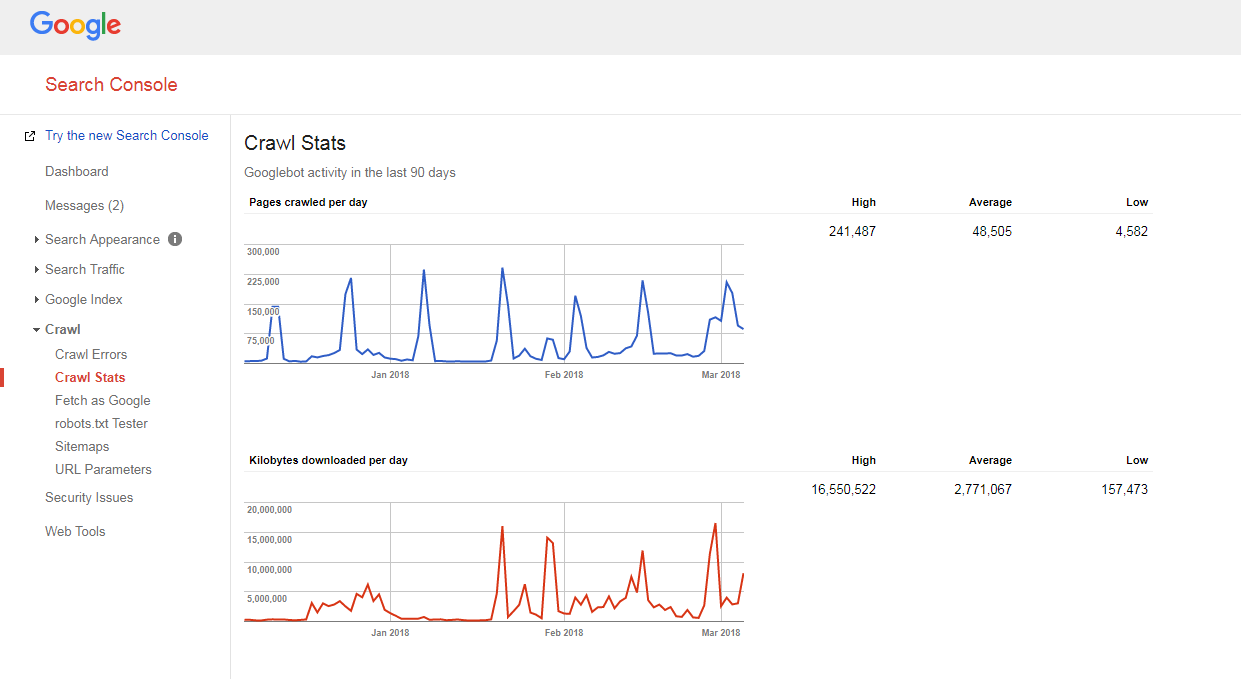 If the number you have got is bigger than 10 (there are 10x more pages on your site than what Google crawls on a daily basis), we have bad news for you: your website has crawling issues.
If the number you have got is bigger than 10 (there are 10x more pages on your site than what Google crawls on a daily basis), we have bad news for you: your website has crawling issues.
But before you learn how to fix them, you need to understand another notion, that is…
Crawl depth
The depth of crawling is the extent to which Google keeps exploring a website down to a certain level.
Generally, the homepage is considered as level 1, a page that is 1 click away is level 2, etc.
Deep level pages have a lower Pagerank (or don’t have it at all) and are less likely to be crawled by Googlebot. Usually, the search engine doesn’t dig down deeper than level 4.
In the ideal scenario, a specific page should be 1-4 clicks away from the homepage or the main site categories. The longer the path to that page is, the more resources the search engines need to allocate to reach it.
If being on a website, Google estimates that the path is way too long, it stops further crawling.
Optimizing crawl depth and budget
To prevent Googlebot from slowing down, optimize your website crawl budget and depth, you need to:
- fix all 404, JS and other page errors;
An excessive amount of page errors can significantly slow down the speed of Google’s crawler. To find all the main site errors, login into your Google (Bing, Yandex) Webmaster Tools panel and follow all the instructions given here.
- optimize pagination;
In case you have too long pagination lists, or your pagination scheme doesn’t allow to click further than a couple of pages down the list, the search engine crawler is likely to stop digging down such a pile of pages.
Also, if there are few items per such page, it can be considered as thin-content one, and won’t be crawled through.
- check navigation filters;
Some navigation schemes may come with multiple filters that generate new pages (e.g. pages filtered by layered navigation). Although such pages may have organic traffic potential, they can also create unwanted load on the search engine crawlers.
The best way to solve this is to limit systematic links to the filtered lists. Ideally, you should use 1-2 filters maximum. E.g. if you have a store with 3 LN filters (color/size/gender), you should allow systematic combination of only 2 filters (e.g., color-size, gender-size). In case you need to add combinations of more filters, you should manually add links to them.
- Optimize tracking parameters in URLs;
Various URL tracking parameters (e.g. ‘?source=thispage’) can create traps for the crawlers, as they generate a massive amount of new URLs. This issue if typical for pages with “similar products” or a “related stories” blocks, where these parameters are used to track users’ behavior.
To optimize crawling efficiency in this case, it’s advised to transmit the tracking information behind a ‘#’ at the end of the URL. This way, such a URL will remain unchanged. Additionally, it’s also possible to redirect URLs with tracking parameters to the same URLs but without tracking.
- remove excessive 301 redirects;
Say, you have a big chunk of URLs that are linked to without a trailing slash. When the search engine bot visits such pages, it gets redirected to the version with a slash.
Thus, the bot has to do twice as much as it’s supposed to, and eventually it can give up and stop crawling. To avoid this, just try to update all the links within your site whenever you change URLs.
Crawl priority
As said above, Google prioritizes websites to crawl. So it’s no wonder it does the same thing with pages within a crawled website.
For the majority of websites, the page with the highest crawl priority is the homepage.
However, as said before, in some cases that can also be the most popular category or the most visited product page. To find the pages that get a bigger number of crawls by Googlebot, just look at your server logs.
Although Google doesn’t officially announce that the factors that can assumably influence the crawl priority of a site page are:
- inclusion into an XML sitemap (and add the Priority tags* for the most important pages),
- the number of inbound links,
- the number of internal links,
- page popularity (# of visits),
- PageRank.
But even after you’ve cleared the way for the search engine bots to crawl your website, they may still ignore it. Read on to learn why.
To better understand how crawl priority, watch this virtual keynote by Gary Illyes.
Talking about the Priority tags in an XML sitemap, they can either be added manually, or with the help of the built-in functionality of the platform your site is based on. Also, some platforms support third-party XML sitemap extensions / apps that simplify the process.
Using the XML sitemap Priority tag, you can assign the following values to different categories of site pages:
- 0.0-0.3 to utility pages, outdated content and any pages of minor importance,
- 0.4-0.7 to your blog articles, FAQs and knowledgeable pages, category and subcategory pages of secondary importance, and
- 0.8-1.0 to your main site categories, key landing pages and the Homepage.
Takeaways
• Google has its own vision on the priorities of the crawling process.
• A page that is supposed to get into the search engine Index should be 1-4 clicks away from the homepage, the main site categories, or most popular site pages.
• To prevent Googlebot from slowing down and optimize your website crawl budget and crawl depth, you should find and fix 404, JS and other page errors, optimize site pagination and navigation filters, remove excessive 301 redirects and optimize tracking parameters in URLs.
• To enhance crawl priority of important site page, make sure they are included into an XML sitemap (with Priority tags) and well linked with other site pages, have links coming from other relevant and authoritative websites.
Myth 3. An XML sitemap can solve all crawling and indexation issues.
While being a good communication tool that alerts Google about your site URLs and the ways to reach them, an XML sitemap gives NO guarantee that your site will be visited by the search engine bots (to say nothing of including all site pages into the Index).
Also, you should understand that sitemaps won’t help you improve your site rankings. Even if a page gets crawled and included into the search engine Index, its ranking performance depends on tons of other factors (internal and external links, content, site quality, etc.).
However, when used right, an XML sitemap can significantly improve your site crawling efficiency. Below are some pieces of advice on how to maximize the SEO potential of this tool.
Be consistent
When creating a sitemap, remember that it will be used as a roadmap for Google crawlers. Hence, it’s important not to mislead the search engine by providing the wrong directions.
For instance, you may occasionally include into your XML sitemap some utility pages (Contact Us, or TOS pages, pages for login, restoring lost password page, pages for sharing content, etc.).
These pages are usually hidden from indexation with noindex robots meta tags or disallowed in the robots.txt file.
So, including them into an XML sitemap will only confuse Googlebots, which may negatively influence the process of collecting the info about your website.
Update regularly
Most websites on the Web change nearly every day. Especially eCommerce website with products and categories regularly shuffling on and off the site.
To keep Google well-informed, you need to keep your XML sitemap up-to-date.
Some platforms (Magento, Shopify) either have built-in functionality that allows you to periodically update your XML sitemaps, or support some third party solutions that are capable of doing this task.
For example, in Magento 2, you can the periodicity of sitemap update cycles. When you define it in the platform’s configuration settings, you signal the crawler that your site pages get updated at a certain time interval (hourly, weekly, monthly), and your site needs another crawl.
Click here to learn more about it.
But remember that although setting priority and frequency for sitemap updates helps, they may not catch up with the real changes and not give a true picture sometimes.
That is why make sure that your sitemap reflects all the recently made changes.
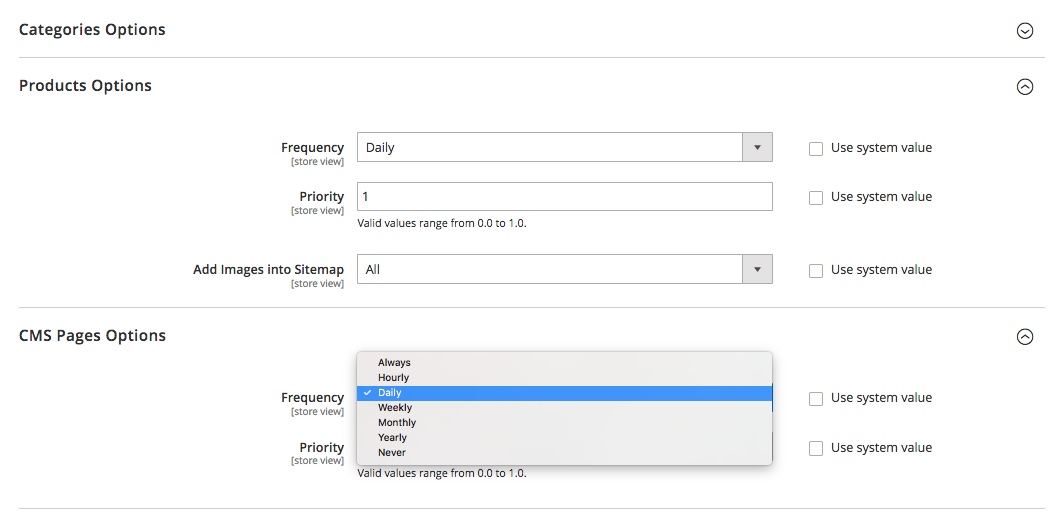 Segment site content and set the right crawling priorities
Segment site content and set the right crawling priorities
Google is working hard to measure the overall site quality and surface only the best and most relevant websites.
But as it often happens, not all sites are created equal and capable of delivering real value.
Say, a website may consist of 1,000 pages, and only 50 of them are «A» grade. The others are either purely functional, have outdated content or no content at all.
If Google starts exploring such a website, it will probably decide that it is quite trashy due to the high percentage of low-value, spammy or outdated pages.
That’s why when creating an XML sitemap, it’s advised to segment website content and guide the search engine bots only to the worthy site areas.
And as you may remember, the Priority tags, assigned to the most important site pages in your XML sitemap can also be of great help.
Takeaways
• When creating a sitemap, make sure you don’t include pages hidden from indexation with noindex robots meta tags or disallowed in the robots.txt file.
• Update XML sitemaps (manually or automatically) right after you make changes in the website structure and content.
• Segment your site content to include only «A» grade pages into the sitemap.
• Set crawling priority for different page types.
That’s basically it.
Have something to say on the topic? Feel free to share your opinion about crawling, indexation or sitemaps in the comments section below.






I thought the section about mentions was fascinating – didn’t realize that Google would pay some attention to this yet in reality, you are right, it makes sense for authoritative purposes.